
最近、新人プログラマさんにオブジェクト指向について教えたりする機会があったのですが、改めて自分の中でも整理する意図も兼ねてブログに説明した内容を記述します。
最初に断っておくと、(きっと多くの人もそうだと思うんだけど)ぼくも誰かから「きっちりした正解を学んだ」わけじゃありません。いろんな本やWebの記事を読んだり実際コーディングしたりしながら「たぶんこんなもんなんだろう」と自分なりに解釈した派です。
なので、ぼくも大いに誤解している可能性もあります。その際は指摘してもらえると嬉しいです。
※そもそも「オブジェクト指向」自体がなり曖昧な表現だとも思っており、いくらでも解釈できるが故に「これが正解!」といえるようなものはないんじゃないかなとも思ってます。
さて、オブジェクト指向とはなにか。
誤解を恐れずに自分の解釈を言えば、それは「整理術」です。それ以上でも、それ以外でもありません。
以下でそう思う理由なども含めて説明していきます。
オブジェクト指向についての定義
オブジェクト指向は表現として曖昧だと書きましたが、一応定義みたいなものが存在しています。それらは、以下の概念によって構成されます。
- カプセル化(情報隠蔽)
- ポリモーフィズム(多態性)
カプセル化とは、簡単に言えば「オブジェクトの内部データはそのオブジェクトにしか扱わせない」というひとつの宣誓です。
そしてポリモーフィズムとは、「オブジェクトがどんな振る舞いをするかそのオブジェクトにまかせる」原則になります。
よく言われる継承については、上のWikipediaには載っていませんね。
きっとそれはポリモーフィズムを実現するための方法のひとつであって、それがオブジェクト指向にとっての必須ではないからでしょう。
あともうひとつ、興味深い内容としてWikipediaにはポリモーフィズムを紹介する前に以下の前置きがあります。
また、オブジェクト指向プログラミングの概念拡大に伴い、必須と表現するのが不適切になりつつあるが、旧来の多くのオブジェクト指向言語が備えている性質には以下のものがある。
たしかに、いろんな言語を見るとかならずしも「ポリモーフィズム」が必須とは思えないようなものもあります。このように記述した根拠としては、JavaScriptをはじめとすふプロトタイプベースの言語には「継承」という概念がないからでしょう。
ただ、ぼくはこの2つはずっと変わることのない必須の概念だと思います。なぜなら、カプセル化とポリモーフィズムとは「メッセージング」というオブジェクト指向の最重要概念を構成するのに必要不可欠だからです。
オブジェクト指向は「整理術」である
カプセル化とポリモーフィズム(=メッセージング)について説明する前に、冒頭で述べた「整理術」について説明します。
オブジェクト指向は「整理術」です。そして、それ以上でもそれ以下でもないとぼくは思っています。
しかし、「なんだただの整理術かよ」なんて侮ってはいけません。それは、ソフトウェア危機以来人類が30年近くかけて作り上げたひとつの叡智の到達点であり、それがなければ今のような複雑なプロジェクトは決して作ることができなかったからです。
オブジェクト指向とは、結局のところ「どのコードを」「どこに」「どのように」配置するかの指針にすぎません。
マシンはオブジェクト指向かどうかなんて気にしません。それどころか、GOTO文が使われていようが構造化されていまいが同じ処理があちこちにあろうがバグがあろうがなかろうが気にしていません。それらは人しか気にしないものです。
言い返せば、それは人のためのノウハウです。それは大規模なプロジェクトになればなるほど重要性が増してきます。
ソフトウェア危機到来
1960年代、プログラマの世界では「ソフトウェア危機」がささやかれていました。
それは、どんどんと複雑化していく処理にソフトウェア工学が追いつかず、いつか全てのプロジェクトが破綻をきたすのではないかという不安が現実味を帯びた時代でもありました。
フレデリック・ブルックス著の「人月の神話」は、ひとつのOSを作るのに5000人年かけたという超巨大プロジェクトを振り返った著です。ソフトウェア危機がささやかれていた時代に、IBMでは推定60メガステップと思われる膨大なコードをほとんど全てアセンブリ(またはそれに近い言語)で作っていました。
予算はアポロ計画よりも多い3兆円ーーちょっとぼくには想像できない世界です。
そのようなプロジェクトも生まれ、ソフトウェア危機はますます現実味を帯びたでしょう。
これ以上複雑なものはもう作れないーーそう言われていた時代、様々な偉人たちがいろんな方向から解決方法を模索されました。
その中から大きく以下の流れが生まれます。
構造化プログラミング
これは、ダイクストラが提唱して今では当たり前になっている手法です。
彼は、全てのプログラムは「順次」「分岐」「反復」の要素で記述ができるとし(構造化定理)、それぞれの処理を3つの構造の連結のみで記述しようと提唱しました。
非構造化プログラミングの代表としては、いわゆる「GOTO」を使ってあちこちに処理が飛び回るものがあります。構造化プログラミングでは、それをやめ、プログラムを上から下に、順を追って記述することで可読性を高めようとしました。
モジュール化
もうひとつの大きな流れとして、モジュール・プログラミングというものがあります。要は「関数」を使ってひとつのまとまった処理をモジュール化するものでした(当時はそれすらなかったのですね)。
VisualBasicでは今でも「Function(関数)」と「Sub(手続き)」という2つのモジュールがあります。
このモジュール化は、その後処理する対象データと関数とを一緒に管理する「クラス」という概念へと進化していきます。
ちなみに、オブジェクト指向の歴史については下記の記事がとても参考になります。
新人プログラマに知っておいてもらいたい人類がオブジェクト指向を手に入れるまでの軌跡
そして、オブジェクト指向へ
ものすごい端折っていますが、こういった流れを統合する形でオブジェクト指向は生まれました。繰り返しになりますが、それは「どこに」「どのコードを」「どのように書くか」の指針(コンパス)です。
ただ、「どこに」「どのコードを」「どのように書くか」という整理は、「構造化プログラミング」でも「モジュール・プログラミング」でもなされていました。
構造化プログラミングは、処理をひとつのまとまりとして順に処理を書くことを説きました。
モジュール・プログラミングは「分割して統治し」、一連の処理ごとにコードを記述することを説きました。
それらと「オブジェクト指向」はどのように異なるのでしょうか。
オブジェクト指向の最大の貢献は、以下の一点で言い表すことができます。
「誰もが直感的にわかる現実というモデル(メタ情報)をコードに落としこんだ」
それは非常に画期的な指針でした。
なぜなら、今までは「機能での分割」はされていても「現実のモデルでの分割」は行われていなかったからです(もちろん前身となるものはあったでしょうが)。機能の場合、その機能によってあらゆる処理が存在しえます。しかし、現実モデルの場合はその物自体が持つ機能は現実によって制限されている上に、どの機能を持っているか直感的に推測しやすいのです。
たとえば「自動飛行制御システム」という機能には、どのような処理がありそうでしょうか。
一方で「自動操縦装置クラス」というモデルクラスの場合、どのような処理がありそうか前者よりも推測しやすいのではないでしょうか(ちょっと例えが稚拙ですが)。
現実のモデルとは、多くの人が直感的に共有できる「メタ情報」です。たとえば何かを出力させたい時、プログラマはPrinterクラスを探すだけで済みます。そのクラスが出力用の動作を持っていることを、人は現実のプリンターが行う動作から直感的に判断することができます。
同時に、プログラマは何をどこにどのように書けば他のプログラマにもわかりやすくなるかの指針も手に入れました。こうして、ソースコードは整理されていったのです。
ここまでカプセル化とかの話がでてきてない件について
ここまで超簡単に歴史を振り返る中では、カプセル化やらポリモーフィズムやらの記述をしませんでした。
というのも、まずはオブジェクト指向の目的について記述したかったからです。
では、どのようにそれを実現するのでしょうか。
「カプセル化」と「ポリモーフィズム」はその「目的」を実現するための手法です。
次に、それぞれに単体でついてもう少し詳しく見てみましょう。
カプセル化について──データの隠蔽
カプセル化についてよく言われるのが、アクセス修飾子を使ってデータのアクセス権限をクラスの中だけに留めることが挙げられます。
要はクラス内のメンバ変数をprivateにして、他からは呼べなくすることです。
そして、中の変数をいじりたい場合、外からはそのクラスが持つメソッドを呼ぶ以外に方法がないようにします。
言ってしまえばそれだけです。簡単ですね。
でも、そうすると何がいいのでしょう。
たとえば、ありきたりな例ですが以下のような銀行口座の処理を考えてみます。
まずは全てグローバルな状態で記述してみましょう(面倒なのでJavaで記述します)。
public class Account {
public String account;
public int zandaka;
}
class Main {
public static void main(String[] arg) {
Account a = new Account();
a.account = "000000";
a.zandaka = 10000;
// 預金を下ろす
int hikidasi = 5000;
if(a.zandaka >= hikidasi) {
a.zandaka -= hikidasi;
exit 0;
}
exit 1;
}
}
みるからに恐ろしいですね。
この程度なら、バグがあったとしてもすぐに見つけ出せるかもしれません。
ただ、もしこんな処理が数万行にもなっていたらどうでしょう。
そして、もし期待する残高になっていなかったら。
その場合は数万行全てを確認する必要がでてきます。あらゆる場所でzandakaはアクセスできてしまうのですから、あらゆる場所でバグが入り込む危険性があります。しかもaccountも自由に書き換えることができちゃいます。
そこで、カプセル化ですよ。
public class Account {
private final String account;
private int zandaka;
public Account(String account, int zandaka) {
this.account = account;
this.zandaka = zandaka;
}
public final boolean hikidasi(int hikiasi) {
if (zandaka >= hikidasi) {
zandaka -= hikidasi;
return true;
}
return false;
}
}
class Main {
public static void main(String[] arg) {
Account a = new Account("000000", 10000);
// 預金を下ろす
if(a.hikidasi(5000)) {
exit 0;
}
exit 1;
}
}
これで、accountは最初のインスタンス作成時にしか定義できないし、残高を引く箇所も1箇所のみになります。バグが発生したら残高を引く箇所と呼び出している箇所だけ見たらいいわけです。簡単ですね。
ところで、これとオブジェクト指向ってどう関連があるんでしたっけ?
どっちもクラスを使ってます。違うのはアクセス権限だけです。実をいうと、カプセル化しただけの場合オブジェクト指向とはいえません。
そして、よく本では「カプセル化はこれだ!」みたいな感じで上記の説明がされていますが、
カプセル化の真髄はこれじゃありません。そのことについては、後述します。
ちなみに、前にも記事に書いたのですが、ぼくはgetter/setterが嫌いです(´・ω・`)
それを使うだけで、上記の「バグが発生したら、残高を引く箇所と呼び出している箇所だけ見たらいい」が通用しなくなっちゃいますからね。
ポリモーフィズムについて──多態性
さて、次にあげるのがこのポリモーフィズムです。
ぼくとしてはこっちのほうがオブジェクト指向としては重要だと思っています。ただ、やっぱりこれだけでもオブジェクト指向とは言えません。
このポリモーフィズムとは何者かというと、最初にも書いたように「オブジェクトがどんな振る舞いをするかそのオブジェクトにまかせる」方法です。
そのためには、たとえば「継承」を使います。
public abstract class Animal {
public abstract void run();
}
public class Dog extends Animal {
public void run(){};
public void bark(){};
}
public class Cat extends Animal {
public void run(){};
public void claw(){};
}
// 使い方
Animal dog = new Dog();
Animal cat = new Cat();
dog.run();
cat.run();
よくポリモーフィズムとして使われる安易な例ですが、両方共Animal型で定義をしているのに、ここで実際に呼ばれるのはDog#run()とCat#run()になります。
これもまあ、言ってしまえばそれだけです。簡単ですね。
ただ、入門書などでこういうのを読んで「一体何がいいの???」となる人は少なくないのではないでしょうか。
「結局DogクラスもCatクラスでもnewしてるじゃん。だったらそれ呼び出せばいいじゃん」と。しかも、上記の場合はdog#bark()もcat#claw()も呼び出すことができません。え、何でこんなことする必要あるの??
それに、結局これもオブジェクト指向とどう関連があるんでしたっけ?
カプセル化とポリモーフィズム=オブジェクト指向ではない
さて、オブジェクト指向はただ「カプセル化」と「ポリモーフィズム」ができていたらできるというわけではありません。現に世の中にはカプセル化などはできててもおよそオブジェクト指向とは思えないような代物も多く存在しています(たぶんぼくもよく作っちゃってます)。
現実というモデルにオブジェクトを当てはめて、効果的に機能させるには、カプセル化とポリモーフィズムを使ってどのようなオブジェクトを形成するかの、もうひとつの大きな骨格となる概念が必要です。
そこで、メッセージングですよ
オブジェクト指向にとっては、この「メッセージング」こそが最重要概念になります。
ただ、いろんなオブジェクト指向の入門書などではこの「メッセージング」について触れていない(あるいはすぐに流してしまう)ものが多い気がします。理由として、わかりづらさがあるのでしょう。
実際「メッセージング」というのはよくわからない概念です。なぜならJavaのように今一般的に使われている言語の場合、ソースコード上に明確に現れないのですから
たとえばJavaの場合、メッセージングとメソッドはほぼ同義となります。その違いは、ソースコードには現れません。
ならメソッドと何が違うのかというと、それはーー
たぶんプログラマの気の持ちようです。
まじか
「気の持ちようなんて言われてもわかんねーし」って思われるかもしれませんが…だってJavaとかの場合ソースコード上に現れないんだから仕方ないじゃない(´・ω・`)
ただ、メソッドとメッセージングには明らかに違う点があります。
それは「呼び出し元は呼び出し先が何してるのか一切関与しないし、何返されても関与しない」という点です。何をしているのかなんて呼び出し元は知らないし、知っていてはいけません。そして、返された値にいちゃもんをつけてはいけませんし、相手側もいちゃもんをつけられるようなものを返してはいけません。
箇条書きすると、以下のようになります。
- 呼び出し元は呼び出し先がどのデータをいじるのか関心がない
- 呼び出し元は呼び出し先がどんな型を返すかしか関心がない
(またはそれさえも関心がない) - 呼び出し元は別の呼び出し先に出力結果をそのまま渡す
それは完璧なカプセル化とポリモーフィズムによってのみ実現されます。2つの概念はセットで初めて効果を持ち、切り離すことはできません。
そして、この「関心の分離」こそがカプセル化の真髄であり、ポリモーフィズムの真髄でもあり、オブジェクト指向の真髄だともいえます。
上で書いたのを思い出してください。
カプセル化とは、簡単に言えば「オブジェクトの内部データはそのオブジェクトにしか扱わせない」というひとつの宣誓です。そしてポリモーフィズムとは、「オブジェクトがどんな振る舞いをするかそのオブジェクトにまかせる」原則です。どちらにしても、呼び出し元はデータについても処理についても一切の関与はしません。
一切関与しないというのは、一体どのようにして実現できるのでしょう。
たとえば、以下のようなケースは関心の分離ができていません。
これは、結局のところ「一部の処理を分離」しているに過ぎません。
Calculator a = new CalculatorImpl();
Data data = a.calcData();
if(data.getXXX() == 1) {
...
} else {
...
}
一方、全ての処理を分離できているものというのはどういうものでしょうか。
たとえば、以下のようなものかなと思ってます。
Calculator a = new CalculatorImpl(); Data data = a.calcData(); Visitor b = new VisitorImpl(data); b.visit();
上記で、CalculatorとVisitorはインタフェースとします。
最初との違いは、以下に表わすことができます。
- 前の出力がそのまま次の入力になっている
- 委託したデータを呼び出し元で再評価するようなことをしない
つまり、あるデータに関する処理は全て相手に任せちゃう。
ここでは、たとえばDRY(Don’t Repeat Yourself)の思想のもとで共通化したメソッドをあちこちから呼び出しながら結局はメイン関数の中で処理を組み立てていくといった手法とは全く別のアプローチをしています。彼らはそれぞれがデータに責任をもちながら、処理を形成していきます。
このプログラムは、ただどの順にどのインタフェースを持つクラスを呼び出し、どの命令を呼ぶか以外に興味がありません。別の言い方をすれば、呼び出すインタフェースとその順序にのみ責任を持っています。データがどのように処理されて渡した先でもどう処理するかはそれぞれのクラスに一任し、そのクラスはそれぞれに渡されたものに責任を持ちます。
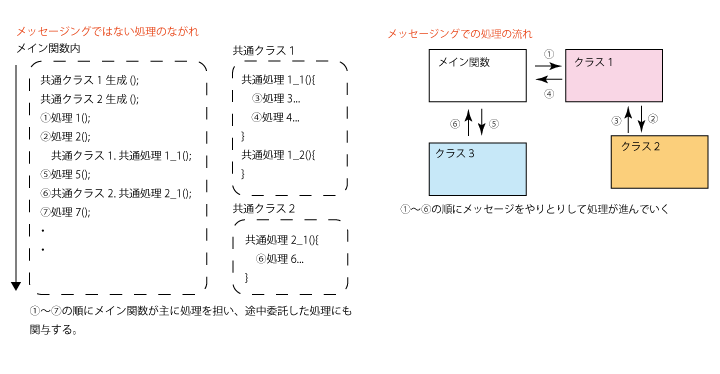
前の出力が次の入力になるというのは、「メッセージング=通信のやりとり」という点でもしっくりとくるのではないでしょうか。逆にデータを呼び出し元が取捨選択したり加工したりしてから全部または一部を渡すというのは、どうも検閲が入ってるっぽい感じがしますよね。
そして、それこそがオブジェクト指向なのだと思います。メッセージングが行えるオブジェクトは皆、周りと独立しており、まるで生きているようにメッセージを奏で始めるからです。
まるで「タイタンの妖女」に出てくるハーモニウムみたいに。
彼らは弱いテレパシー能力を持っている。彼らが送信し受信できるメッセージは、水星の歌に近いほど単調だ。彼らはおそらく二つのメッセージしか持っていない。(中略)
最初のそれは、「ボクハココニイル、ココニイル、ココニイル」
第二のそれは、「キミガソコニイテヨカッタ、ヨカッタ、ヨカッタ」カート・ヴォネガッド著ーータイタンの妖女
改めて、オブジェクト指向って?
ここで、もう一度最初に戻ってこの問について答えてみようと思います。
オブジェクト指向でいうオブジェクトとは、突き詰めると以下のように定義できるんじゃないかと思っています。
「現実をモデルとし、メッセージングを行える単位にまで整理した構造体」
そのためには「カプセル化」と「ポリモーフィズム」という二つの方法を手段として用います。
ところで、この「メッセージング」とは、そのまま「世界」に存在するほとんど全ての物質(=オブジェクト)や概念に当てはめることができるのではないでしょうか。
たとえば、車を運転するにしても人は車がどういう構造をしてるのかなんていちいち知っておく必要はありません。ただ「アクセルを踏む」「ハンドルを回す」というメッセージを車に送っているだけです。もし車を運転するのに運転手側が内部構造の制御を常にしなければならないとしたら、それは非常に使いづらいものでしょう。
ここまで、概念的な話ばかりしてきたので、次回はもっと具体的な例を使って説明しようと思います。
ピンバック: オブジェクト指向プログラミングの具体例(入門編) | たそがれブランチ
とてもわかりやすく大変ためになった。
ありがとうございます。